
By Usama Jamil
8 min read
The Real Role of LLMs in Medical AI
Large language models are becoming one of the most talked-about technologies in healthcare. But the real story is not about replacing doctors. It is about reducing language-heavy work, improving clinical workflows, and building systems that are useful, safe, and grounded in evidence.
Healthcare has always been a language business before it becomes a data business. A patient explains symptoms. A clinician writes a note. A specialist reviews a referral. A care team documents a discharge. An insurer reads a claim. So when large language models, or LLMs, started getting good at understanding and generating text, healthcare was always going to be one of the first serious testing grounds. The World Health Organization says health-related uses already span diagnosis and clinical care, patient guidance, clerical tasks, education, and scientific research. That alone explains why LLMs in medical AI have moved from curiosity to strategic priority so quickly.
But medicine is not a field where fluent output is enough. In most industries, a confident-sounding answer can be annoying. In healthcare, it can be dangerous. That is why the conversation around medical AI has matured so quickly. The same WHO guidance that highlights the promise of large multimodal models also warns about inaccurate outputs, bias, automation bias, privacy risks, and cybersecurity concerns. In other words, the opportunity is real, but so is the risk.
That is also why the most realistic near-term value of LLMs is not fully autonomous diagnosis. It is workflow support.
Why healthcare is such a natural fit for LLMs
Healthcare runs on unstructured text. Clinical notes, patient messages, discharge summaries, radiology reports, referral letters, medication instructions, guidelines, prior authorizations, and insurance documentation are all language-heavy processes. LLMs are particularly well suited to summarizing, drafting, extracting, organizing, and translating this kind of information. WHO specifically includes documenting and summarizing patient visits inside electronic health records as one of the main health applications for these systems.
This matters because clinicians are still dealing with a major administrative burden. The American Medical Association reports that 45.2% of physicians in its 2023 national dataset experienced at least one symptom of burnout. That number is lower than the 2021 peak, but it is still high enough to keep efficiency, staffing, and documentation burden at the center of healthcare operations.
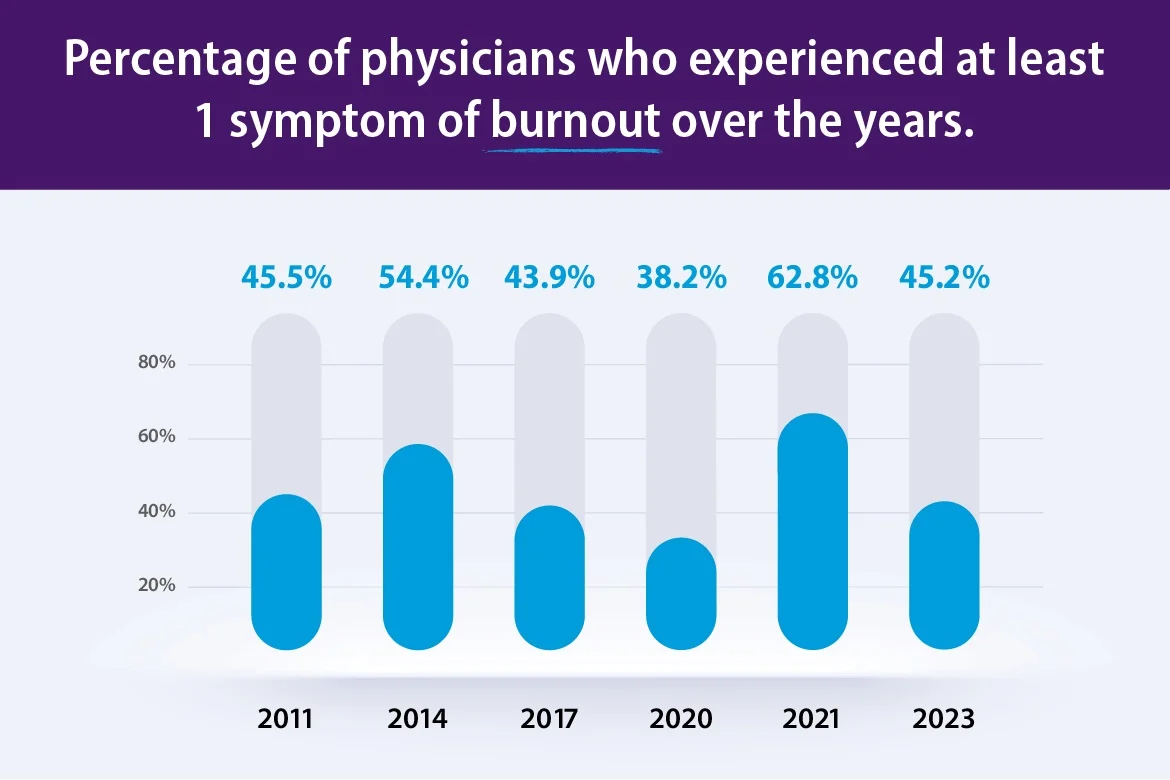
So when people ask where LLMs fit into medical AI, the strongest answer today is simple: anywhere language overload is taking time away from care.
Where the value is already starting to show
The early wins are showing up in the least glamorous parts of medicine, which is usually a good sign: inbox replies, chart summarization, documentation support, data extraction, and first-draft communication. These are not the use cases that get headlines, but they are often the ones that create real operational relief.
A good example comes from Stanford Health Care. In a 2024 JAMA Network Open quality improvement study, 162 clinicians used an EHR-integrated LLM to draft patient inbox replies over a five-week period. The mean draft utilization rate was 20%, and the study reported statistically significant reductions in some burden and burnout-related measures, even though message time metrics did not significantly change. That is a very healthcare kind of result: not flashy, not magical, but operationally meaningful. A tool does not need to replace a clinician to be valuable. It only needs to reduce the number of repetitive tasks that drain attention every day.
The broader evidence points in the same direction. A 2025 systematic review of real-world clinical workflow implementations found only four peer-reviewed studies through April 2025, which shows how early the field still is. But those studies already covered outpatient communication, mental health support, inbox message drafting, and clinical data extraction, with reported gains in efficiency, satisfaction, and workload reduction. The review also highlighted the limits: variability across data types, weak generalizability, regulatory delays, and limited post-deployment monitoring.
That balance is important. Medical AI does not need to be perfect everywhere to be useful somewhere. But every useful deployment still has to be scoped carefully.
The Difference Between Impressive and Deployable
This is where the hype usually outruns the evidence.
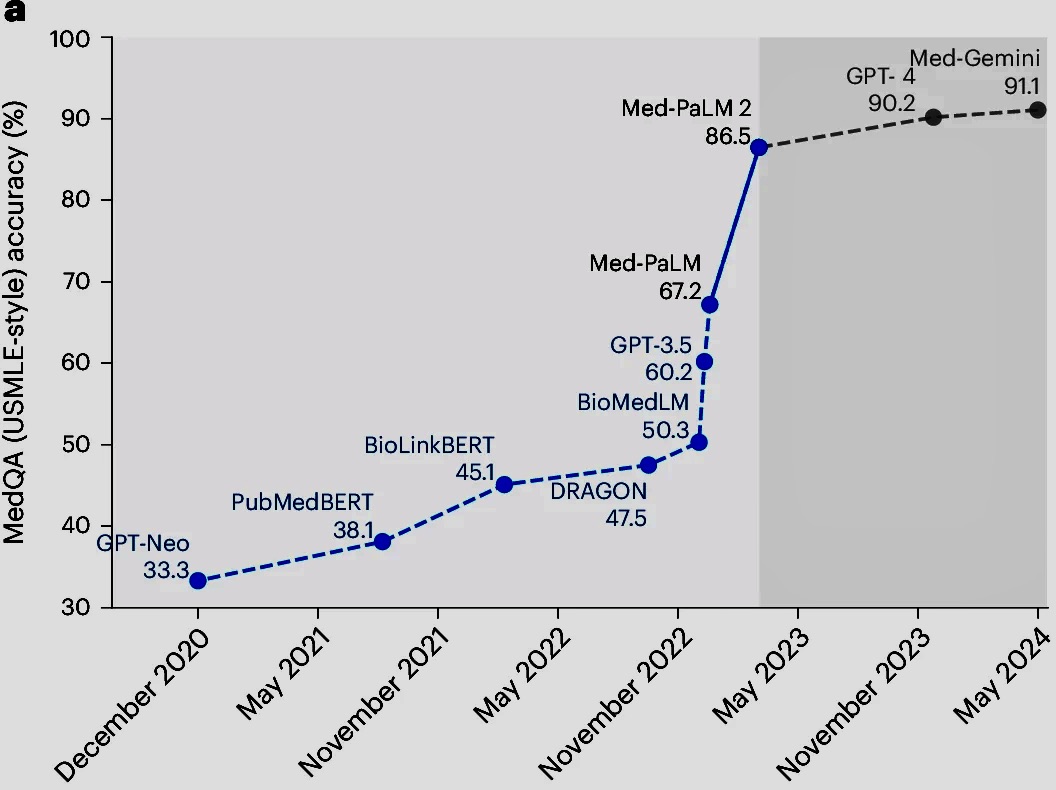
On medical benchmarks, LLMs have become genuinely impressive. Google reports that Med-PaLM 2 reached 86.5% accuracy on the MedQA medical exam benchmark, and the associated Nature Medicine paper says that in a pilot study using real-world medical questions, specialists preferred Med-PaLM 2 answers over generalist physician answers 65% of the time. Those are serious numbers, and they show how far medical language modeling has come.
But the same paper makes the bigger point: specialist answers were still preferred over the model's answers about 60% of the time. That means strong benchmark performance does not equal expert-level clinical judgment in live care settings. The gap between "good on a test" and "safe in a hospital" is still wide.
That gap shows up clearly in the research landscape. A 2025 JAMA systematic review of 519 healthcare LLM studies found that only 5% used real patient care data for evaluation. Most studies focused on question answering and medical knowledge tasks, while fairness, bias, toxicity, deployment considerations, and calibration were measured far less often. In other words, the field has produced a lot of exciting results, but much less evidence about how these models behave inside actual healthcare delivery.
This is one of the most important facts in medical AI right now. The research volume is growing fast, but real-world clinical evidence is still thin.
Why Human Oversight Still Matters
The safest path forward is not to treat LLMs as digital doctors. It is to treat them as tightly scoped systems that support specific tasks under human oversight.
WHO's guidance pushes in exactly that direction. It recommends designing health applications for well-defined use cases, building in oversight, protecting privacy, and auditing performance after release. That is the right mindset for medical AI more broadly. A system that drafts a patient-friendly explanation of lab results is very different from a system that recommends treatment for a high-risk condition. The burden of evidence should rise with the level of risk.
Regulators are also signaling that this space is still evolving. The FDA says it is exploring methods to identify and tag medical devices that incorporate foundation models, including LLMs and multimodal systems, so providers and patients can recognize when that functionality is present. That is a practical transparency move, but it is also a signal that oversight frameworks are still being adapted to this new generation of tools.
So the right deployment model is becoming clearer. Start with narrow tasks. Use human review. Measure outcomes locally. Watch for bias and drift. Keep an audit trail. Treat clinical safety as a product feature, not a compliance checkbox.
A Quick Reality Check for Healthcare Teams
Use this simple checklist before adopting LLMs in a medical workflow:
- Is the use case narrow and clearly defined?
- Can a human reviewer validate the output quickly?
- Is the task administrative, communication-heavy, or documentation-heavy?
- Is there a clear process for handling errors?
- Can performance be measured over time?
- Are privacy, compliance, and data security addressed?
- Is the team using the model to support decisions rather than blindly automate them?
The more boxes you can check, the more realistic the deployment is likely to be.
What the next phase of medical AI will probably look like
The most believable future is not one where LLMs replace clinicians. It is one where they quietly become the language layer across healthcare systems.
That means first-draft replies to patient messages. Cleaner chart summaries. Faster prior authorization support. Better extraction from unstructured notes. Easier literature review. More readable patient education. More efficient handoffs between teams. In some cases, it will also mean decision support. But the systems that last will be the ones that combine model capability with retrieval, workflow design, evaluation, and clear human accountability.
That distinction matters. Healthcare does not reward systems for sounding smart. It rewards systems for being reliable, explainable, and safe enough to trust.
Final thoughts
The biggest mistake in the LLM-in-healthcare debate is asking whether these models can replace doctors. That framing is too shallow, and honestly, too distracting. The better question is whether they can reduce the low-value language burden that keeps skilled clinicians buried in administrative work while preserving the judgment, context, and accountability that medicine depends on.
So far, that is where the real promise is. Not artificial doctors. Better clinical workflows. Not less human care. More room for humans to deliver it.